Vision-language models (VLMs) excel at multimodal understanding, yet their text-only decoding forces them to verbalize visual reasoning, limiting performance on tasks that demand visual imagination. Recent attempts train VLMs to render explicit images, but the heavy image-generation pre-training often hinders the reasoning ability. Inspired by the way humans reason with mental imagery—the internal construction and manipulation of visual cues—we investigate whether VLMs can reason through interleaved multimodal trajectories without producing explicit images. To this end, we present a Machine Mental Imagery framework, dubbed as Mirage, which augments VLM decoding with latent visual tokens alongside ordinary text. Concretely, whenever the model chooses to ``think visually'', it recasts its hidden states as next tokens, thereby continuing a multimodal trajectory without generating pixel-level images. Begin by supervising the latent tokens through distillation from ground-truth image embeddings, we then switch to text-only supervision to make the latent trajectory align tightly with the task objective. A subsequent reinforcement learning stage further enhances the multimodal reasoning capability. Experiments on diverse benchmarks demonstrate that Mirage unlocks stronger multimodal reasoning without explicit image generation.
Vision-language models (VLMs) currently rely on text-only decoding, which limits their performance on tasks requiring visual imagination. Existing attempts to train VLMs to render explicit images often hinder their reasoning ability. These limitations led to a research question:
Can VLMs reason benefit from, weaving compact visual information into the text stream and dispensing with the need for explicit image generation?
Inspired by human mental imagery, we introduce Mirage, a framework that enables VLMs to reason through interleaved multimodal trajectories without producing explicit images. Our solution, Mirage, augments VLM decoding with latent visual tokens alongside ordinary text, allowing the model to "think visually" by recasting its hidden states as next tokens, thereby continuing a multimodal trajectory without generating pixel-level images
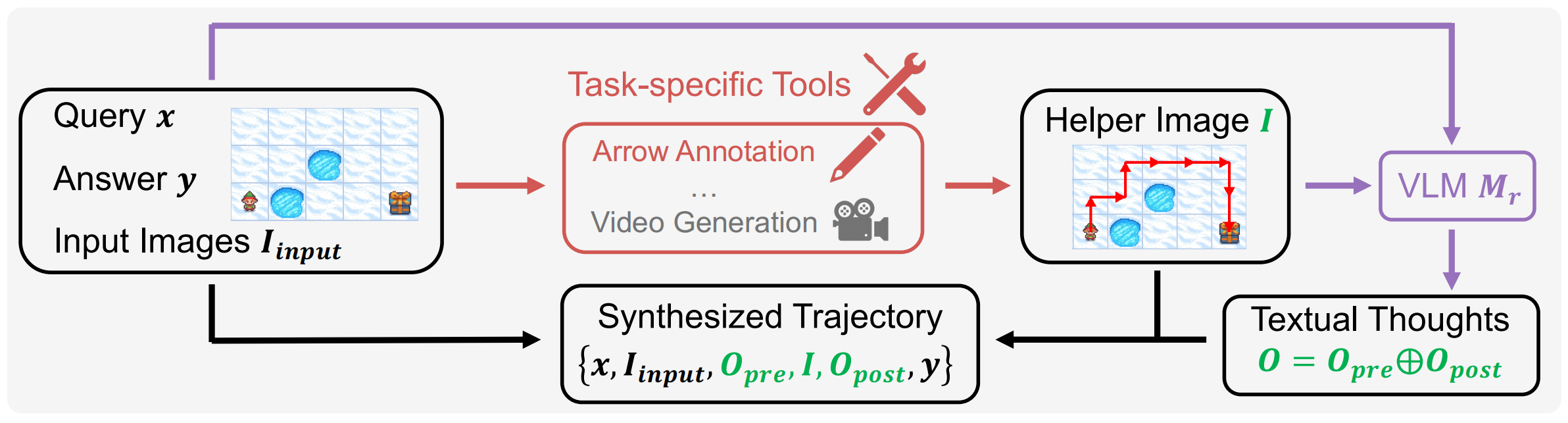
A training corpus is synthesized where each input is paired with a task-specific helper image that provides precise visual cues. Then, a large reasoning VLM is prompted with the original input, ground-truth answer, and the helper image to generate a step-by-step reasoning chain that incorporates the helper image.
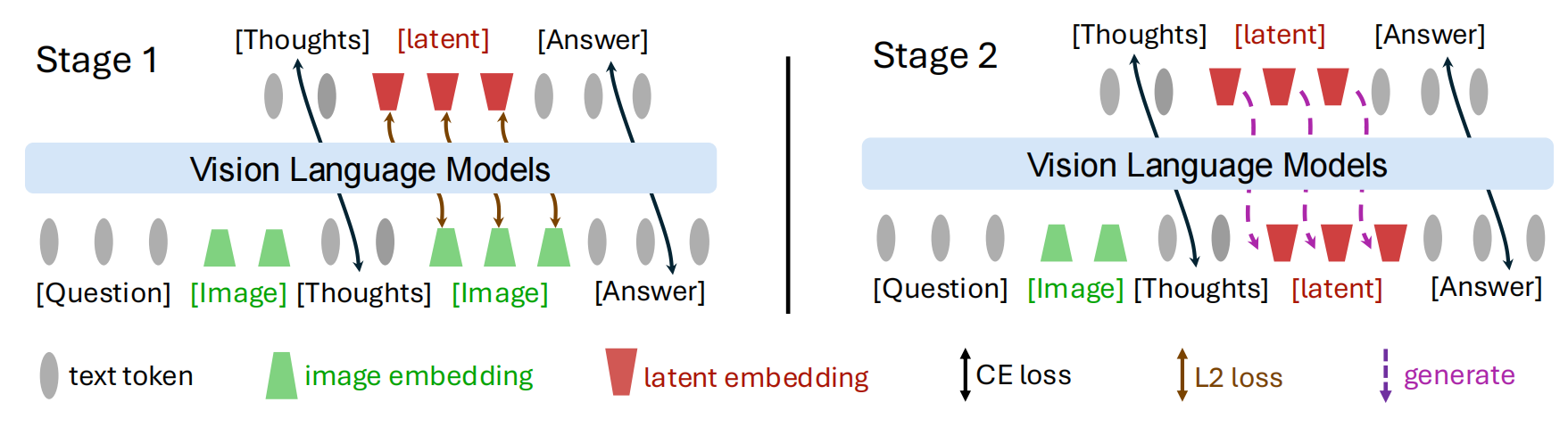
The training of Mirage involves a two-stage fine-tuning paradigm to enable interleaved reasoning. The first stage jointly supervises text and latent visual tokens, grounding the latter in the visual subspace, while the second stage removes direct supervision on the latent vectors, allowing them to adapt as priors for subsequent text generation.
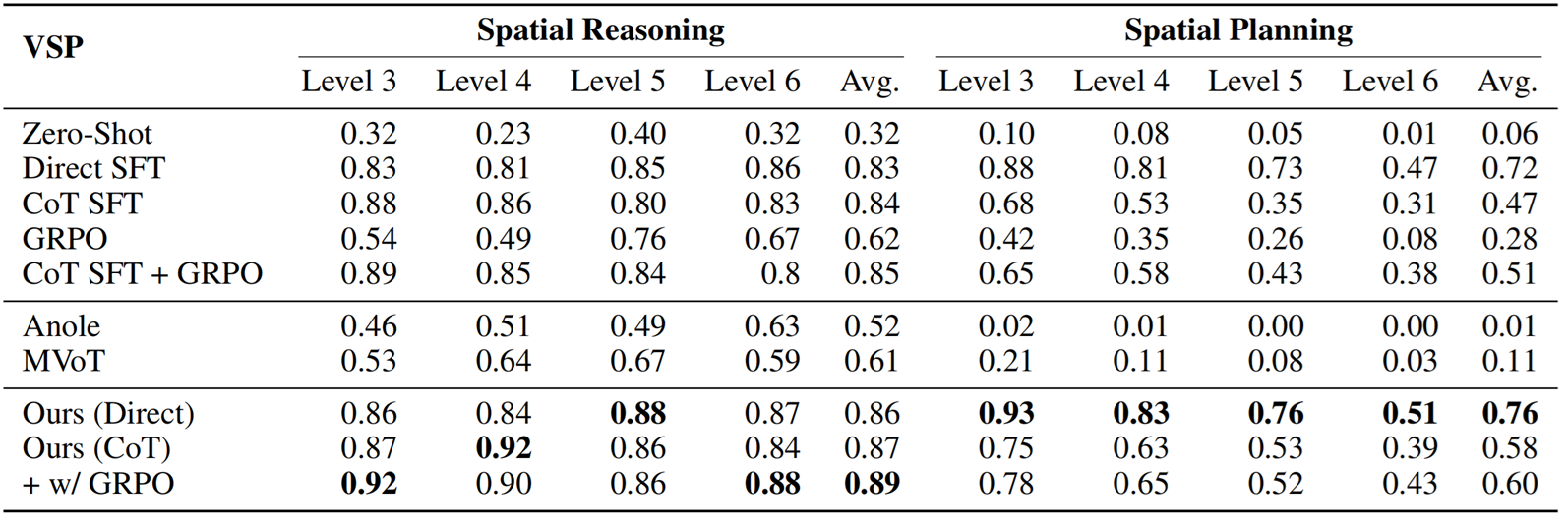
Mirage significantly enhances the reasoning capability of 7B VLMs on VSP tasks, leading to improved accuracy compared to text-only baselines and existing unified models.




@arxiv{yang2025mirage,
title={Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens},
author={Zeyuan Yang and Xueyang Yu and Delin Chen and Maohao Shen and Chuang Gan},
year={2025},
eprint={2506.17218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.17218},
}